Table Of Contents
- Terraform
- Installation
- Configuration
- Providers
- Resources
- Variables
- Locals
- Data Sources
- If statements, Loops, Expressions
- Modules
- Building Infrastructure
- Destroying Infrastructure
- Project Structure
- Gotchas
- References
Terraform
Terraform is an infrastructure as code tool that helps to provision and manage any cloud, infrastructure, or service.
It allows you to version your infrastructure and automate provisioning.
You can plan and predict changes, create reproducible infrastructure and create shared modules for common infrastructure patterns.
Installation
Download latest terraform package and extract it to a folder in your system.
Add the location to your system’s PATH.
Verify your installation by running below command.
$ terraform -help
Usage: terraform [-version] [-help] <command> [args]
The available commands for execution are listed below.
Configuration
Version Constraints
You’ll probably integrate terraform with your CI/CD pipeline to provision your infrastructure.
So, it’s good practice to pin down on the versions of terraform and aws provider to be used so that you don’t pick up any latest releases which might have introduced breaking changes.
We’ll make use of terraform configuration block to specify these settings. Let’s create versions.tf file with these settings.
terraform {
# Terraform CLI version to be used
required_version = "0.12.8"
# Provider versions to be used
required_providers {
aws = ">= 2.33.0"
template = "~> 2.0"
null = "~> 2.0"
local = "~> 1.3"
}
}
Constraint operators allowed:
| Operators | Purpose |
|---|---|
| = | exact version equality |
| != | version not equal to |
| >, >=, <, <= | version comparison, where “greater than” is a larger version number |
| ~> | allows specified version, plus newer versions that only increase the most specific segment of specified version number For example, ~> 0.9 is equivalent to >= 0.9, < 1.0 |
Remote State File
Terraform must store state about your managed infrastructure and configuration. This state is used by Terraform to map real world resources to your configuration, keep track of metadata, and to improve performance for large infrastructures. This state is stored by default in a local file named terraform.tfstate.
It is good practice to store this file remotely in S3. Terraform will make use of this remote file to create plans and make changes to your infrastructure.
Advantages of using remote state file:
- Shared storage for state files
- Locking state files to prevent concurrent updates by multiple team members
- Isolation to prevent accidental impact to infrastructure
Usually, enterprises will set up separate accounts for development and production which makes it easy for them to manage access at account level.
So, your S3 bucket for storing the state files will vary for each of your accounts. You will need some flexibility in providing them.
Let’s add a partial backend configuration block to terraform.tf file.
terraform {
# Partial backend configuration
backend "s3" {}
}
You can then create multiple backend configuration files for each of your account to specify the S3 bucket which is to be used for storing state files.
It is recommended to create a state file per AWS component for providing isolation and sharing of state files. So, we provide different S3 keys for the storing state files of each component.
Below is a typical S3 bucket layout for storing state files pertaining to each component.
rharshad-prod-terraform-state (s3 bucket)
=========================================
iam/
├─ group/
├─ role/
├─ user/
│ ├─ developer/
│ │ ├─ terraform.tfstate
├─ policy/
route53/
s3/
├─ log-storage/
│ ├─ terraform.tfstate
├─ terraform-state/
│ ├─ terraform.tfstate
vpc/
├─ terraform.tfstate
Let’s consider we have two AWS accounts for dev and prod respectively. We’ll create two files namely dev.backend.tfvars & prod.backend.tfvars with below sample configuration which will mention the respective S3 buckets to be used for state files.
Here, we are asking terraform to store the state file for iam policies in S3 path iam/policies/terraform.tfstate.
dev.backend.tfvars
# s3 bucket to be used for state files
bucket = "rharshad-dev-terraform-state"
key = "iam/policies/terraform.tfstate"
# region of S3 bucket
region = "us-east-1"
# enable server side encryption of state file
encrypt = true
prod.backend.tfvars
# s3 bucket to be used for state files
bucket = "rharshad-prod-terraform-state"
key = "iam/policies/terraform.tfstate"
# region of S3 bucket
region = "us-east-1"
# enable server side encryption of state file
encrypt = true
When you are ready to create your infrastructure, you’ll specify the backend configuration file to be used via CLI options. Terraform will then get the S3 bucket and region details to store the state files there.
Typical file layout for the terraform project will be as below:
environments/
├─ dev/
│ ├─ dev.backend.tfvars
├─ prod/
│ ├─ prod.backend.tfvars
versions.tf
terraform.tf
State Locking
There could be other team members who might be working on updates to the same infrastructure code. It could lead to corruption of state.
To prevent multiple writes to the state file, you could lock the state and release it once you are done. Terraform AWS provider plugin uses DynamoDB for locking to prevent concurrent operations.
Update the backend file with the dynamodb_table to be used for state locking.
prod.backend.tfvars
# s3 bucket to be used for state files
bucket = "rharshad-prod-terraform-state"
key = "iam/policies/terraform.tfstate"
# region of S3 bucket
region = "us-east-1"
# name of a DynamoDB table to use for state locking and consistency. The table must have a primary key named LockID
dynamodb_table = "rharshad-prod-terraform-state-lock"
# enable server side encryption of state file
encrypt = true
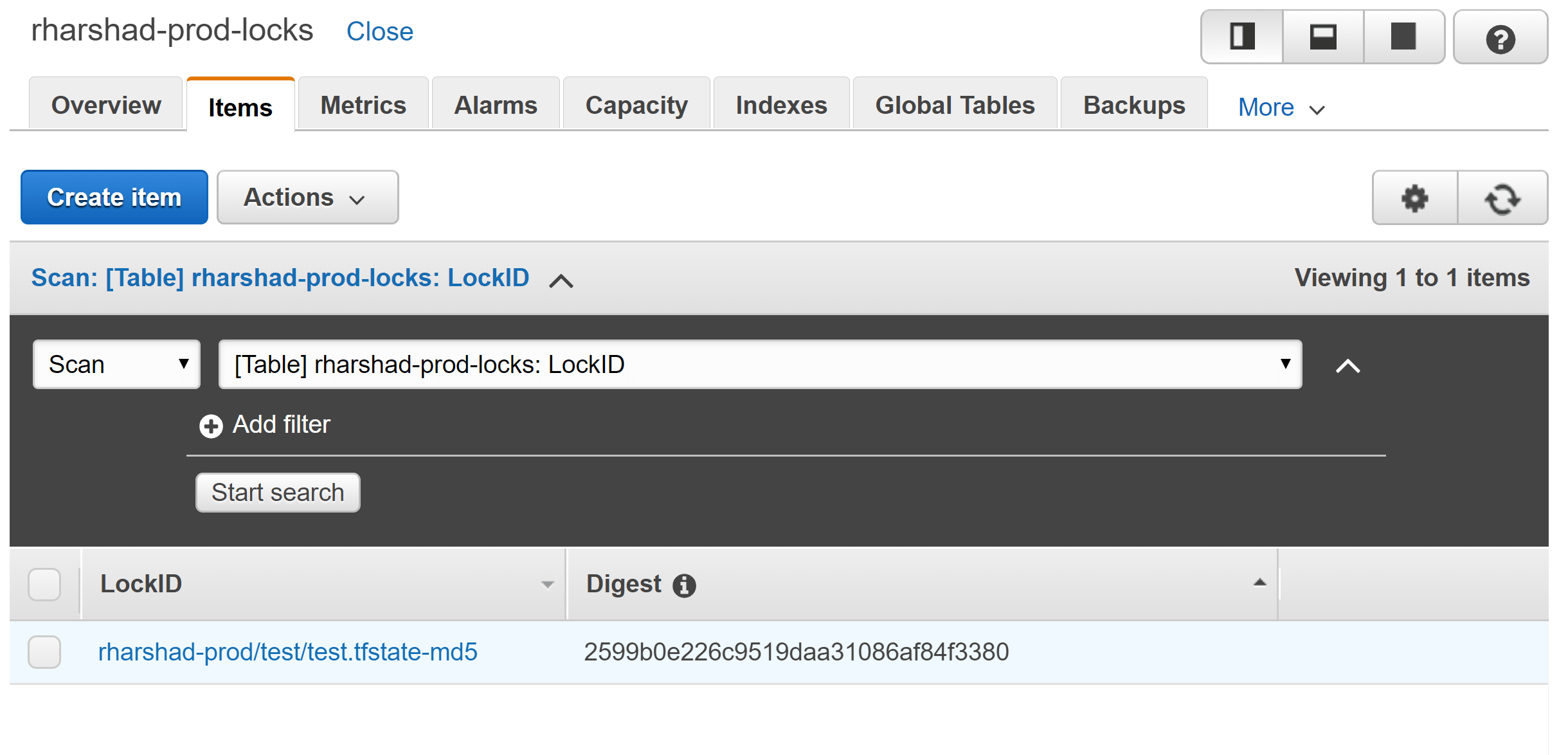
Now, we create the dynamo db table with primary key as LockID. When you run terraform it will create/update entries in the table as shown below for the respective backend state file.
Providers
Previously, we had defined version constraint for aws provider plugin but we haven’t defined the configuration for it.
provider block is used to configure aws provider which is responsible for creating and managing resources.
AWS providers are region specific and you can define multiple providers.
Let’s create a new file named providers.tf and add below configuration.
# Default provider configuration
provider "aws" {
region = "us-east-1"
}
# Additional provider configuration with alias
provider "aws" {
alias = "uw2"
region = "us-west-2"
}
# Additional provider configuration with alias
provider "aws" {
alias = "ew1"
region = "eu-west-1"
}
provider "local" {
version = "~> 1.3"
}
provider "null" {
version = "~> 2.1"
}
provider "template" {
version = "~> 2.1"
}
Wherever you want to create the resources, you need to specify the provider to be used. You can make use of the alias to indicate it.
If you don’t specify the provider, then the one without the alias is treated as default provider by terraform.
Resources
resource block defines a resource that exists within the infrastructure. Resource can be an EC2 instance, IAM roles, security groups or any such logical resource in AWS.
Let’s say we want to create an IAM role with permissions policy for a beanstalk application. We can create an EC2 instance profile using the resource block as follows:
iam.tf
# create an IAM role with trust policy to ec2 service
resource "aws_iam_role" "ec2_role" {
name = "beanstalk-ec2-role"
# Trust policy that allows EC2 to assume role and get temporary credentials for usage in application
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { "Service": "ec2.amazonaws.com"},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
# create an IAM policy that allows read and write operations to S3 and attach it to an IAM role
resource "aws_iam_role_policy" "ec2_permissions" {
name = "beanstalk-ec2-permissions-policy"
role = aws_iam_role.ec2_role.name
policy = <<EOF
{
"Version": "2012-10-17",
"Statement":[
{
"Sid":"AllowReadWriteOperationsOnS3Buckets",
"Action":[
"s3:Get*",
"s3:List*",
"s3:PutObject*"
],
"Effect":"Allow",
"Resource":[
"arn:aws:s3:::elasticbeanstalk-*",
"arn:aws:s3:::elasticbeanstalk-*/*",
"arn:aws:s3:::rharshad-prod-data",
"arn:aws:s3:::rharshad-prod-data/test/*"
]
}
]
}
EOF
}
# create an instance profile and attach it to a role with permissions policy
resource "aws_iam_instance_profile" "ec2_instance_profile" {
name = "beanstalk-ec2-instance-profile"
role = aws_iam_role.ec2_role.name
}
Notice that we didn’t specify the region provider to be used. In this case, terraform will use the default provider which we had configured earlier.
Available resources, examples and supported arguments can be found at:
https://www.terraform.io/docs/providers/aws/
Attributes
Resource instances managed by Terraform each export attributes whose values can be used elsewhere in configuration.
For example, incase of aws_iam_role, terraform exports attributes such as arn, id which are available only upon resource creation.
Such values which are available only at runtime are exported by terraform and you can use them in other resources which require them for their creation.
Attributes which are exported are mentioned under each resource in terraform doc.
https://www.terraform.io/docs/providers/aws/
Dependencies
Resources might be dependant on other resources. For example, in iam.tf file, aws_iam_role_policy needs an iam role name to be specified.
Here, it is dependant on aws_iam_role resource. aws_iam_role exports an attribute name which is the name of the role created.
We could use terraform’s interpolation syntax to access the attribute exported by the resource aws_iam_role.
The syntax to access an attribute from a resource is <TYPE>.<NAME>.<ATTRIBUTE>.
Here,
| Component | Explanation | Actual Value |
|---|---|---|
| TYPE | Resource type | aws_iam_role |
| NAME | Name given for the resource | ec2_role |
| ATTRIBUTE | Attribute exported by the resource which you want to access | name |
Example,
resource "aws_iam_instance_profile" "ec2_instance_profile" {
name = "beanstalk-ec2-instance-profile"
# role name is given by accessing the attribute exported from another resource
role = aws_iam_role.ec2_role.name
}
Terraform interprets these implicit dependencies and decides on the resource creation order. It will decide that aws_iam_role needs to be created first, followed by aws_iam_instance_profile as it is dependant on the role name.
Explicit dependencies
Sometimes, the dependencies between resources are not visible to terraform. In such cases, use depends_on to explicitly declare the dependency.
Note: depends_on can’t be used for module blocks in terraform 0.12 and older versions
data "aws_eks_cluster" "eks" {
name = var.cluster_name
depends_on = [module.cni_role]
}
Lifecycle
By default, Terraform detects any difference in the current settings of a real infrastructure object and plans to update the remote object to match configuration.
In some rare cases, settings of a remote object are modified by processes outside of Terraform, which Terraform would then attempt to “fix” on the next run. In order to make Terraform share management responsibilities of a single object with a separate process, the ignore_changes meta-argument specifies resource attributes that Terraform should ignore when planning updates to the associated remote object.
For example, you might set the environment variables for your lambda by a process managed outside of terraform. In that case, when you re-run your terraform update it will remove the environment variables set on the lambda as they are not specified in your terraform configuration. In order to avoid this you can use the ignore_changes meta-argument by specifying the resource attributes which need to ignored when performing change detection:
resource "aws_lambda_function" "lambda" {
# ...
lifecycle {
# ignores changes to environment
ignore_changes = [environment]
}
}
Note: Ignore changes can’t be used to specify attributes defined inside sets e.g. beanstalk option settings https://github.com/hashicorp/terraform/issues/22504
Variables
We had specified names like beanstalk-ec2-instance-profile, beanstalk-ec2-role etc. for the resources. AWS requires each resource to have unique names.
To make this code truly shareable we can make use of variables feature offered by terraform. It allows you to parameterize the configurations.
For example, we could define a variable block as:
variables.tf
variable "name" {
type = string
description = "Unique name for the resources"
}
Refer https://www.terraform.io/docs/configuration/variables.html for full list of variables.
When you run your terraform command to create the infrastructure, you will have to provide values for these variables.
Variable Definitions File
In case, you have lot of variables and they vary based on the account/environment, you can create a variables file and provide the file to be used to terraform.
prod.tfvars
name=test
You can move the variables file to each environment folder. Your typical project layout will be as shown below:
environments/
├─ dev/
│ ├─ dev.backend.tfvars
│ ├─ dev.tfvars
├─ prod/
│ ├─ prod.backend.tfvars
│ ├─ prod.tfvars
versions.tf
terraform.tf
Accessing Variable Values
We can update our iam.tf to make use of the variable with the help of interpolation syntax var. prefix followed by the variable name.
Note: Interpolation syntax varies based on the variable type.
resource "aws_iam_instance_profile" "ec2_instance_profile" {
name = "${var.name}-ec2-instance-profile"
# role name is given by accessing the attribute exported from another resource
role = aws_iam_role.ec2_role.name
}
Locals
A local value assigns a name to an expression, allowing it to be used multiple times within a module without repeating it.
One use case for using locals would be tags. We might want to tag all of our AWS resources so that we can have cost reports for each application.
We could define the common tags in locals block and refer it in all the resources thereby avoiding duplication.
locals {
common_tags = {
Application = var.name
Environment = var.env
CostCenter = "4357902130"
Owner = "test@example.com"
}
}
resource "aws_elastic_beanstalk_environment" "default" {
...
tags = local.common_tags
}
Data Sources
Data sources allow data to be fetched or computed for use elsewhere in Terraform configuration. Use of data sources allows a Terraform configuration to make use of information defined outside of Terraform.
Let’s say we need to create a beanstalk app. The resource requires solution_stack_name to be specified.
AWS retires platform versions and introduces new versions from time to time. It is not desirable to hardcode the stack name as it might get retired.
Ideally, we might want to get the latest stack which is supported by AWS and create our resource based on it while sticking to our app requirements.
You could use aws_elastic_beanstalk_solution_stack data source provided by terraform to get information on stacks available based on your app requirements.
data "aws_elastic_beanstalk_solution_stack" "java_with_tomcat" {
most_recent = true
# Regex to return stacks which are based on Java with Tomcat where the Java version needs to be 8 with any minor release updates
name_regex = "^64bit Amazon Linux (.*) Tomcat (.*) Java 8.(.*)$"
}
Remote State
Another use case of data sources is that you can use it to read remote state files.
Let’s say you have a vpc named 045fsfdsf in your AWS account. It is bad practice to hard code the VPC to be used in all your app’s terraform configuration files.
Instead, you could create your VPC using terraform and export the value as a output (refer modules section) in your state file stored in S3.
Your state file will be as below when you export output values.
{
"version": 1,
"terraform_version": "0.12.8",
"outputs": {
"vpc_id": "045fsfdsf"
}
}
You could then in your respective applications, access this state file to get the vpc name.
Note: You need to update your modules to produce the required outputs so that you can access them in your dependant child modules using the data source block.
# configure vpc remote state file as a data source
data "terraform_remote_state" "vpc" {
backend = "s3"
config = {
bucket = "rharshad-prod-terraform-state"
key = "vpc/terraform.tfstate"
region = "us-east-1"
}
}
# pseudocode to access vpc id from remote state file using interpolation syntax data.<TYPE>.<NAME>.outputs.<OUTPUT_NAME>
# you need to update your vpc module to produce an output named vpc_id to be able to access it in a different module as a datasource
vpc_id = "${data.terraform_remote_state.vpc.outputs.vpc_id}"
When you create a new VPC and want all of your apps to start using it, all you have to do is publish your state file with the change.
You could then apply the changes to your apps by running terraform commands which will download the remote state files again and detect this change thereby re-creating the resources in the new VPC.
If statements, Loops, Expressions
Refer below article which extensively covers using statements, loops in terraform.
https://blog.gruntwork.io/terraform-tips-tricks-loops-if-statements-and-gotchas-f739bbae55f9
Modules
Let’s say we need to create a beanstalk application in multiple regions. We could simply write a resource block for it.
There are two problems with this approach.
-
Terraform requires us to specify the region provider to be used for creating a resource. So, we will end up writing the resource block multiple times for each region thereby duplicating the code.
-
Your organization might have multiple apps. Each of these apps might want to create beanstalk resource. You will end up writing resource blocks in each of these apps.
There is lack of organization & reusability and this is where terraform modules comes to the rescue.
Modules in Terraform are self-contained packages of Terraform configurations that are managed as a group. Modules are used to create reusable components, improve organization, and to treat pieces of infrastructure as a black box.
Remote Module
You can have your module defined in it’s own git repo. At a basic level, it will have below files.

| File | Purpose |
|---|---|
| data.tf | Defines data to be fetched or computed by terraform. |
| main.tf | Defines your resource blocks. It could be split into multiple terraform files as well. |
| outputs.tf | Defines return values of your module. Here, you will define return values which might be needed by other resources. |
| variables.tf | Defines parameters needed for the module. |
Let’s create a reusable beanstalk module which we can refer in all our apps.
main.tf
resource "aws_elastic_beanstalk_environment" "default" {
name = var.env_name
application = var.app_name
description = var.description
solution_stack_name = var.solution_stack
### ENVIRONMENT SETTINGS ###
dynamic setting {
for_each = var.env_settings
content {
namespace = setting.value[0]
name = setting.value[1]
value = setting.value[2]
resource = ""
}
}
tags = var.tags
}
variables.tf
variable "app_name" {
description = "The name of the application in which the environment needs to be created"
}
variable "env_name" {
description = "Name for elastic beanstalk environment"
}
...
Outputs file for example could export the ELB name of the created beanstalk resource.
outputs.tf
output "elb" {
value = aws_elastic_beanstalk_environment.default.load_balancers[0] : ""
}
Once you are done release your changes by tagging them. We will use the tag to version the module.
Import & Usage of Remote Module
Now, let’s say our app needs beanstalk to be set up in two AWS regions. We could use the module which we had created before to pass the input values and have the beanstalks created.
To import the module, we use the source argument inside the module block by specifying the Git url of the repo and the tag.
Other arguments specified within the module block are treated as input variables for the module.
beanstalk.tf
# uses default provider to create beanstalk in us-east-1 region
module "beanstalk_us_east_1" {
source = "git::ssh://git@github.com:HarshadRanganathan/beanstalk-module.git?ref=v0.1"
# module arguments
app_name = local.app_name
env_name = local.env_name
description = local.env_description
solution_stack = data.aws_elastic_beanstalk_solution_stack.java_with_tomcat.name
env_settings = local.beanstalk_settings
tags = local.beanstalk_tags
}
# uses provider with alias uw2 to create beanstalk in us-west-2 region
module "beanstalk_us_west_2" {
source = "git::ssh://git@github.com:HarshadRanganathan/beanstalk-module.git?ref=v0.1"
# module arguments
app_name = local.app_name
env_name = local.env_name
description = local.env_description
solution_stack = data.aws_elastic_beanstalk_solution_stack.java_with_tomcat.name
env_settings = local.beanstalk_settings
tags = local.beanstalk_tags
providers = {
aws = aws.uw2
}
}
When you run this terraform file, terraform will download the remote modules into .terraform folder.
You would have noticed that we are specifying the GIT url twice in the file.
This is because terraform doesn’t support interpolation in the source argument. So, you couldn’t do something like this source = local.beanstalk_module_repo as it will result in error.
Specifying the same module source in multiple places is error prone when you want to update the tag version.
A opinionated workaround is to make use of override.tf file (override specific portions of an existing configuration object in a separate file).
override.tf
module "beanstalk_us_east_1" {
source = "git::ssh://git@github.com:HarshadRanganathan/beanstalk-module.git?ref=v0.1"
}
module "beanstalk_us_west_2" {
source = "git::ssh://git@github.com:HarshadRanganathan/beanstalk-module.git?ref=v0.1"
}
beanstalk.tf
# uses default provider to create beanstalk in us-east-1 region
module "beanstalk_us_east_1" {
# overridden by value given in override.tf file
source = ""
# module arguments
app_name = local.app_name
env_name = local.env_name
description = local.env_description
solution_stack = data.aws_elastic_beanstalk_solution_stack.java_with_tomcat.name
env_settings = local.beanstalk_settings
tags = local.beanstalk_tags
}
# uses provider with alias uw2 to create beanstalk in us-west-2 region
module "beanstalk_us_west_2" {
# overridden by value given in override.tf file
source = ""
# module arguments
app_name = local.app_name
env_name = local.env_name
description = local.env_description
solution_stack = data.aws_elastic_beanstalk_solution_stack.java_with_tomcat.name
env_settings = local.beanstalk_settings
tags = local.beanstalk_tags
providers = {
aws = aws.uw2
}
}
We are still specifying the git url twice in the override file. But, it allows us to maintain all the source url’s in a separate file so that it is maintainable.
Building Infrastructure
Initialization
terraform init initializes various local settings and data that will be used by subsequent commands.
As part of initilization, we provide the backend config to be used.
terraform init -backend-config=environments/prod/prod.backend.tfvars
Generate Plan
We generate the terraform plan by supplying the variables file.
terraform plan -var-file="environments/prod/prod.tfvars" -out=.terraform/tplan
Apply Changes
Once we are happy with the plan that is generated, apply the changes to create/update/delete the infrastructure.
terraform apply .terraform/tplan
Destroying Infrastructure
To generate the plan for destroying the infrastructure, use the -destroy flag.
terraform plan -destroy -var-file="environments/prod/prod.tfvars" -out=.terraform/tplan
As you can see, you will have to specify the input vars file to destroy the infrastructure. You can’t destroy the infrastructure with only the tfstate file.
Refer - https://github.com/hashicorp/terraform/issues/18994
This means that when you have a CI/CD pipeline, you will have to use the same branch (or) release which was used to create the infrastructure so that you can destroy it with the same input variables as terraform validates the config before running destroy.
One workaround is to save the git hash in S3 when you create the infrastructure. When you want to destroy the infrastructure, you can use the git hash to checkout the same code which was used in creation and supply the input vars file to destroy the environment.
If you’re using jenkins pipeline for your CI/CD then you will achieve it using below code snippets:
// when creating the infrastructure save the git commit hash to S3
commitId = sh(returnStdout: true, script: 'git rev-parse HEAD')
writeFile file: "git", text: "${commitId}"
sh "aws s3 cp git s3://<bucket>/<key>/git"
..
// when destroying the infrastructure use the git commit hash stored in S3 and perform code checkout
gitCommitHash = sh(returnStdout: true, script: "aws s3 cp s3://<bucket>/<key>/git - | head -1")
checkout scm: [
$class: 'GitSCM',
branches: [[name: gitCommitHash]],
userRemoteConfigs: scm.userRemoteConfigs
]
Project Structure
Let’s look at some of the project structures for terraform.
Simple Structure
At the simplest form, your project will consist of terraform files in the root folder categorized based on their purpose.
All the variables and backend files will be placed inside their respective environment folders.
environments/
├─ dev/
│ ├─ dev.backend.tfvars
│ ├─ dev.tfvars
├─ prod/
│ ├─ prod.backend.tfvars
│ ├─ prod.tfvars
├─ shared.tfvars
versions.tf
terraform.tf
variables.tf
providers.tf
outputs.tf
main.tf
data.tf
Complex Structure
Your project might need local reusable modules to reduce code duplication but at the same time provide flexibility by defining multiple modules with varying levels of complexity.
So, you might go with this structure where the common modules are defined inside modules directory. Each of the main modules have their own environment specific variables file.
modules/
├─ policy/
│ ├─ main.tf
│ ├─ outputs.tf
│ ├─ variables.tf
policies/
├─ route53/
│ ├─ main.tf
│ ├─ data.tf
│ ├─ outputs.tf
│ ├─ providers.tf
│ ├─ variables.tf
│ ├─ versions.tf
│ ├─ environments/
│ │ ├─ prod/
│ │ │ ├─ prod.tfvars
│ │ │ ├─ prod.backend.tfvars
├─ s3/
│ ├─ main.tf
│ ├─ data.tf
│ ├─ outputs.tf
│ ├─ providers.tf
│ ├─ variables.tf
│ ├─ versions.tf
│ ├─ environments/
│ │ ├─ prod/
│ │ │ ├─ prod.tfvars
│ │ │ ├─ prod.backend.tfvars
There is one problem with the above structure though. Your providers and versions file are duplicated for each of the main module.
So, you will have to update the versions across the duplicated files. Also, the data sources file can be reused across the other modules but they are duplicated as well.
You could go with below structure to overcome the cons but it adds some additional effort to make it work.
modules/
├─ policy/
│ ├─ main.tf
│ ├─ outputs.tf
│ ├─ variables.tf
policies/
├─ route53/
│ ├─ main.tf
│ ├─ outputs.tf
│ ├─ variables.tf
│ ├─ environments/
│ │ ├─ prod/
│ │ │ ├─ prod.tfvars
│ │ │ ├─ prod.backend.tfvars
├─ s3/
│ ├─ main.tf
│ ├─ outputs.tf
│ ├─ variables.tf
│ ├─ environments/
│ │ ├─ prod/
│ │ │ ├─ prod.tfvars
│ │ │ ├─ prod.backend.tfvars
data.tf
providers.tf
versions.tf
main.tf
variables.tf
outputs.tf
In above structure, we have removed the duplication of versions and data sources file. However, the variables and outputs file are duplicated. This is because terraform will display the outputs only if they are defined in the root path from where you run your commands.
In the previous structure, we could run any of the modules separately by running the terraform commands inside those specific modules. But here, we have to run the command from the root path.
So, we need to update our main.tf to be able to select specific modules for execution. Unfortunately, modules don’t support count parameter. Only, resources support it.
In our modules we could pass in a variable such as enabled and then use the count parameter in the resource block to decide if we need to execute or not.
main.tf in root path
module "route53_policy_execution" {
source = "./policies/route53"
enabled = var.policy == "route53" ? true : false
name = var.name
}
So, if we want to execute route53 policy we could use this command:
terraform apply -var-file="policies/route53/environments/prod/prod.tfvars"
In the corresponding variable file prod.tfvars:
policy = "route53"
so that the condition in the corresponding module will get matched.
Next problem is how to show conditional outputs based on specific module execution. To solve this, we could check for specific attributes in the output block and return a map.
outputs.tf in root path
output "route53" {
value = length(module.route53_policy_execution.arn) > 0? map(
"id", module.route53_policy_execution.id[0],
"arn", module.route53_policy_execution.arn[0]
) : null
}
We have reduced the duplication but added some complexity. So, it’s up to you to decide which structure suits your team.
Gotchas
Workspaces
When Terraform is used to manage larger systems, teams should use multiple separate Terraform configurations that correspond with suitable architectural boundaries within the system so that different components can be managed separately and, if appropriate, by distinct teams.
Named workspaces allow conveniently switching between multiple instances of a single configuration within its single backend.
Let’s say you have multiple remote state backends for each environment.
You could think that you will create a workspace for each of them and then switch conveniently between them without affecting each other.
But the big gotcha here is that workspaces operate within a single backend. So, switching between workspaces doesn’t switch the backend.
https://github.com/hashicorp/terraform/issues/16627