Table Of Contents
- Introduction
- Why GraphQL
- Project
- Maven Dependency
- Queries
- Schema
- Providers
- DataFetchers
- Runtime Wiring
- Serving over HTTP
- SDL Directives
- Tools
- References
Introduction
GraphQL is a query language for APIs and give clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
Why GraphQL
Let’s look at some existing protocols/architectural styles to understand the problems that graphql addresses.
SOAP
SOAP is a standardized protocol to send messages using HTTP, SMTP and is maintained by W3C.
Pros:
- Single endpoint used for retrieving data
- ACID compliance
- SOAP protocol is supported by a lot of technologies like ws-security etc.
Cons:
- SOAP supports only XML format which must be parsed to be read and consumes more bandwidth.
- More complex
- No caching
REST
REST is an architectural style that defines a set of recommendations for designing loosely coupled applications that use the HTTP protocol for data transmission.
Pros:
- Better performance
- Deliver data in HTML, XML, JSON, YAML message formats
- API calls can be cached
Cons:
- Data over-fetching/under-fetching (Server driven selection)
- N+1 queries
GraphQL
Pros:
-
Strong data typing (schemas) -> customer knows exactly what is offered
-
Single endpoint for retrieving data -> integration simplified
-
Client data definition allows fetching exactly the requested data -> reduces network payload and increases application performance
-
Search on multiple databases with a single query -> reduce complexity
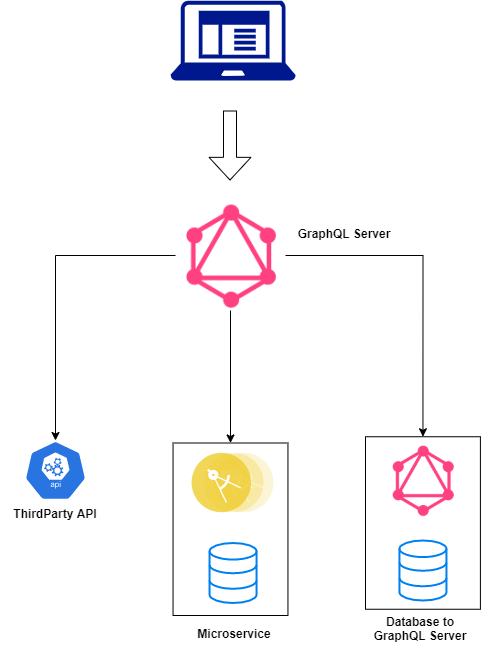
Project
For this guide, we will build a book details application based on spring boot.

Code for this guide is available at Github:

Maven Dependency
We add below dependencies to our pom.xml to get started with GraphQL and Spring Boot application.
<!-- Provides default configurations for our spring boot application and a complete dependency tree -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/>
</parent>
<properties>
<java.version>1.8</java.version>
<graphql.java.version>13.0</graphql.java.version>
<graphql.java.spring.boot.starter.webmvc.version>1.0</graphql.java.spring.boot.starter.webmvc.version>
</properties>
<dependencies>
<!-- Spring boot starter for building RESTful application -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- GraphQL java dependency -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java</artifactId>
<version>${graphql.java.version}</version>
</dependency>
<!-- GrpahQL Java Spring Boot Starter artifact provides a HTTP endpoint on ${graphql.url} with the default value "/graphql" just by being on the classpath -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-spring-boot-starter-webmvc</artifactId>
<version>${graphql.java.spring.boot.starter.webmvc.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Queries
You can check out the ways in which you can query the GraphQL API in below doc as it is beyond the scope of this guide.
https://graphql.org/learn/queries/
Schema
Schema in GraphQL is the central contract between the client and the server, describing all the types of data and all the operations (queries and mutations) upon those types the server offers.
SDL
A GraphQL service is created by defining types and fields on those types, then providing functions for each field on each type.
Every GraphQL service defines a set of types which completely describe the set of possible data you can query on that service. Then, when queries come in, they are validated and executed against that schema.
Object Types
The most basic components of a GraphQL schema are object types, which just represent a kind of object you can fetch from your service, and what fields it has.
type Book {
title: String
pageCount: Int
}
Here,
-
Bookis an object type -
titleandpageCountare fields in the object which can be queried and returned in the response -
titleis of typeStringandpageCountis of typeInt
Scalar Types
GraphQL comes with a set of default scalar types out of the box:
- Int: A signed 32‐bit integer
- Float: A signed double-precision floating-point value
- String: A UTF‐8 character sequence
- Boolean: true or false
- ID: The ID scalar type represents a unique identifier, often used to refetch an object or as the key for a cache
type Book {
title: String
pageCount: Int
}
Here String and Int are scalar types for the fields.
Non-Null
You can apply additional type modifiers (as Non-Null by adding an exclamation mark) that affect validation of those values.
type Book {
title: String!
pageCount: Int
}
This means that our server always expects to return a non-null value for the field title, and if it ends up getting a null value that will actually trigger a GraphQL execution error, letting the client know that something has gone wrong.
Lists
We can use a type modifier to mark a type as a List, which indicates that this field will return an array of that type. In the schema language, this is denoted by wrapping the type in square brackets, [ and ]
type Book {
title: String!
pageCount: Int
bookStores: [BookStores]
}
Here, bookStores field is of type list and returns an array of BookStores object values.
Special Types
Most types in your schema will just be normal object types, but there are two types that are special within a schema:
schema {
query: Query
mutation: Mutation
}
Every GraphQL service has a query type which defines the entry point of every GraphQL query.
type Query {
bookById: Book
}
Here, bookById is an entry point to your query and it returns an object of type Book.
Arguments
Every field on a GraphQL object type can have zero or more arguments.
All arguments are named. Arguments can be either required or optional.
type Query {
bookById(id: ID!): Book
}
Here, bookById is expecting a non-null argument id to be supplied. If the argument is not supplied in your query then it will result in error.
Enums
Also called Enums, enumeration types are a special kind of scalar that is restricted to a particular set of allowed values.
This allows you to:
-
Validate that any arguments of this type are one of the allowed values
-
Communicate through the type system that a field will always be one of a finite set of values
enum BookViewReason {
RENT
BUY
CURIOSITY
}
Here we have defined an enum named BookViewReason that will accept only 3 finite values.
To use this enum in an argument you just define it as below:
bookById(id: ID!, reason: BookViewReason): Book
Schema-Driven Development
So, far we learnt about the graphql type system and how it’s defined. Let’s see it in practice for our book details application.
We will define below schema in SDL for our sample book details application.
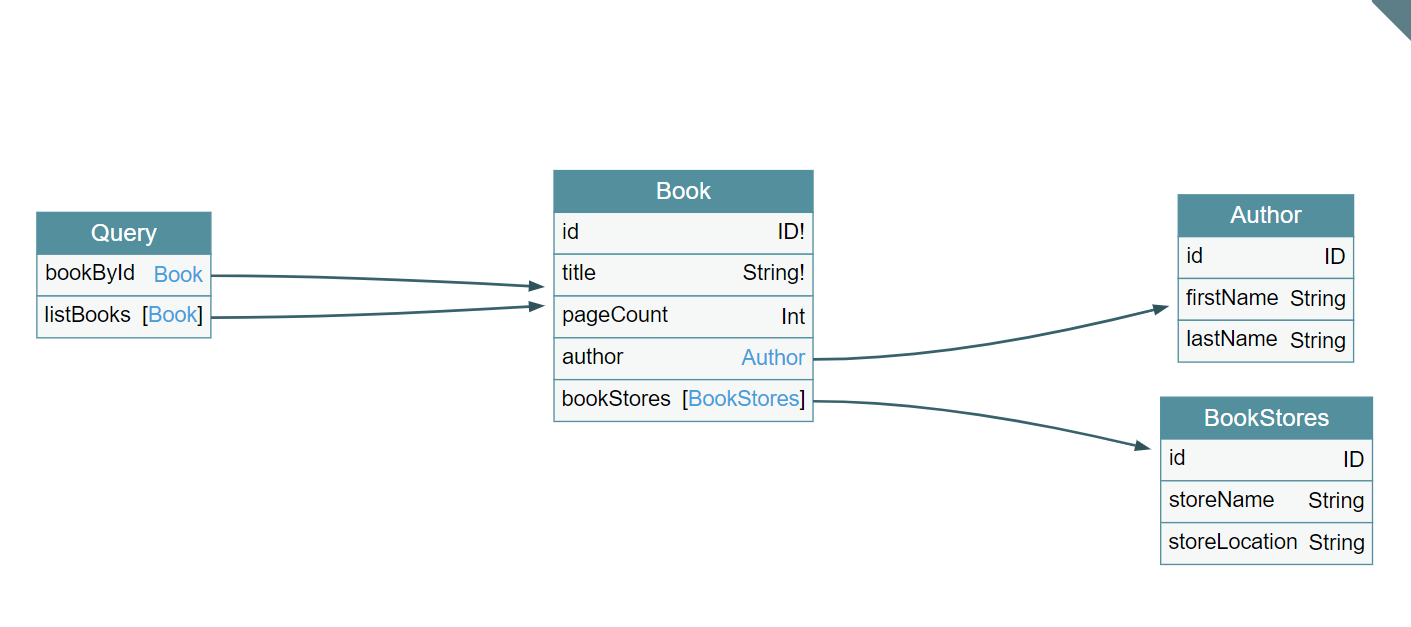
We define a root schema file which defines our query operation:
root.graphqls
schema {
query: Query
}
type Query {
"""
Returns book, author and store details for the provided id
"""
bookById(id: ID!, reason: BookViewReason): Book
"""
Returns list of books truncated by field argument limit
"""
listBooks(limit: Int!): [Book]
}
We have defined two query operations:
| Operation | Description |
|---|---|
| bookById(id: ID!): Book | bookById query operation which returns details about the book, author and book stores which have stock of it. It accepts one argument: id which is mandatory and returns an object of type Book |
| listBooks(limit: Int!): [Book] | listBooks query operation which returns list of available books. It accepts one argument: limit which is mandatory and returns a list of Book objects |
Let’s define our Book object.
book.graphqls
type Book {
id: ID!
title: String!
pageCount: Int
author: Author
bookStores: [BookStores]
}
-
Our
Bookobject has fields id, title, pageCount and two objectsAuthorandBookStores. -
Authorcontains details about the book author andBookStoresis a list which returns details of book stores which have stock of this book.
We define these objects in their respective schema files as follows:
author.graphqls
type Author {
id: ID
firstName: String
lastName: String
}
bookStores.graphqls
type BookStores {
id: ID
storeName: String
storeLocation: String
}
and finally our enum.
bookViewReason.graphqls
enum BookViewReason {
RENT
BUY
CURIOSITY
}
Providers
We define a provider class where we write the logic to parse our schema files.
GraphQLProvider.java
@Component
public class GraphQLProvider {
private GraphQL graphQL;
@Value("classpath:schema/**/*.graphqls")
private Resource[] schemaResources;
@Bean
public GraphQL graphQL() {
return graphQL;
}
@PostConstruct
public void init() {
final List<File> schemas = Arrays.stream(schemaResources).filter(Resource::isFile).map(resource -> {
try {
return resource.getFile();
} catch (IOException ex) {
throw new RuntimeException("Unable to load schema files");
}
}).collect(Collectors.toList());
final GraphQLSchema graphQLSchema = buildSchema(schemas);
this.graphQL = GraphQL
.newGraphQL(graphQLSchema)
.build();
}
private GraphQLSchema buildSchema(final List<File> schemas) {
final SchemaParser schemaParser = new SchemaParser();
final SchemaGenerator schemaGenerator = new SchemaGenerator();
final TypeDefinitionRegistry typeDefinitionRegistry = new TypeDefinitionRegistry();
for (final File schema:schemas) {
typeDefinitionRegistry.merge(schemaParser.parse(schema));
}
final RuntimeWiring runtimeWiring = buildWiring();
return schemaGenerator.makeExecutableSchema(typeDefinitionRegistry, runtimeWiring);
}
private RuntimeWiring buildWiring() {
// to be defined later
}
}
Let’s see what above code does:
We create a GraphQLSchema and GraphQL instance. This GraphQL instance is exposed as a Spring Bean via the graphQL() method annotated with @Bean. The GraphQL Java Spring adapter will use that GraphQL instance to make our schema available via HTTP on the default url /graphql.
We read our multiple schema files and pass it to buildSchema method.
We use TypeDefinitionRegistry merge method to combine all the schema files. We then use the SchemaGenerator to combine the schema definitions and runtime wiring to generate the GraphQLSchema.
We’ll see later what we define inside our buildWiring method.

DataFetchers
Each field in graphql has a graphql.schema.DataFetcher associated with it.
Some fields will use specialised data fetcher code that knows how to go to a database say to get field information while most simply take data from the returned in memory objects using the field name and Plain Old Java Object (POJO) patterns to get the data.
Let’s create GraphQLDataFetchers.java class where we will define data fetchers for our fields.
Initially, we define our in-memory data store which holds data about the books, authors and stores.
Each entry has an unique ID. We link the author and store details to the books store using the id e.g. book-1 has an authorId of author-1 which links to the entry in author map.
@Component
public class GraphQLDataFetchers {
private static List < Map < String, String >> books = Arrays.asList(
ImmutableMap.of("id", "book-1",
"title", "Harry Potter and the Philosopher's Stone",
"pageCount", "223",
"authorId", "author-1",
"bookStores", "store-1,store-3"),
ImmutableMap.of("id", "book-2",
"title", "Moby Dick",
"pageCount", "635",
"authorId", "author-2",
"bookStores", "store-2"),
ImmutableMap.of("id", "book-3",
"title", "Interview with the vampire",
"pageCount", "371",
"authorId", "author-3")
);
private static List < Map < String, String >> authors = Arrays.asList(
ImmutableMap.of("id", "author-1",
"firstName", "Joanne",
"lastName", "Rowling"),
ImmutableMap.of("id", "author-2",
"firstName", "Herman",
"lastName", "Melville"),
ImmutableMap.of("id", "author-3",
"firstName", "Anne",
"lastName", "Rice")
);
private static List < Map < String, String >> stores = Arrays.asList(
ImmutableMap.of("id", "store-1",
"storeName", "ABC Bookstore",
"storeLocation", "Parnell St"),
ImmutableMap.of("id", "store-2",
"storeName", "Rockstone Bookshop",
"storeLocation", "Dublin Castle"),
ImmutableMap.of("id", "store-3",
"storeName", "City Books",
"storeLocation", "Grafton St")
);
}
Now we need to define datafetchers for the fields. Let’s recall our schema definition.
type Query {
bookById(id: ID!): Book
listBooks(limit: Int!): [Book]
}
We had defined two operations bookById and listBooks. We need to define resolvers for them i.e. functions which will get invoked for each of these fields and return objects or scalars.
bookById Data Fetcher
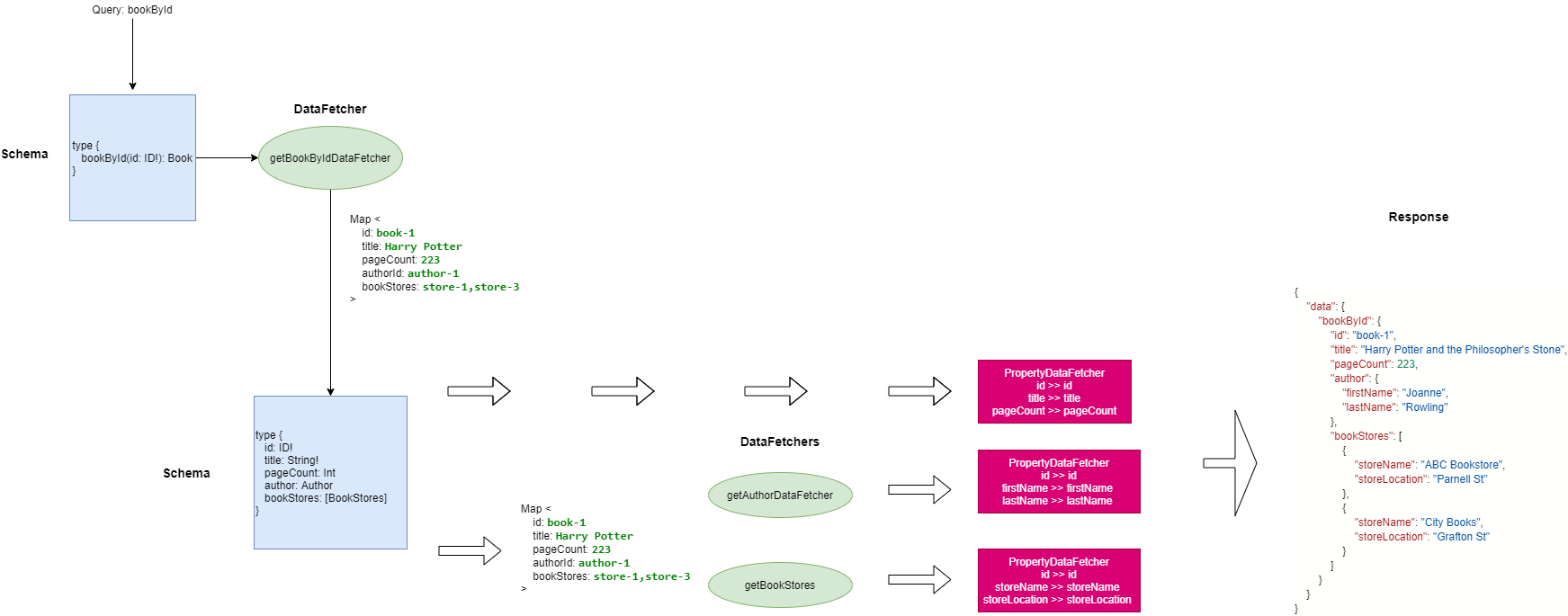
public DataFetcher getBookByIdDataFetcher() {
return dataFetchingEnvironment - > {
final String bookId = dataFetchingEnvironment.getArgument("id");
Map < String, String > bookDetails = books
.stream()
.filter(book - > book.get("id").equals(bookId))
.findFirst().orElse(null);
return DataFetcherResult.newResult()
.data(bookDetails)
.build();
};
}
Let’s explain what the above code does:
Each DataFetcher is passed a graphql.schema.DataFetchingEnvironment object which contains what field is being fetched, what arguments have been supplied to the field and other information such as the field’s type, its parent type, the query root object or the query context object.
We see that for bookById operation an argument called id will get passed. We need to return book details for the matching id.
So, we get the argument value from dataFetchingEnvironment and filter our books map for a matching id. Once we have a match, we return DataFetcherResult with the matched data.
In this case, the data is a map of key value pairs. Datafetcher will resolve the values to the fields defined in the schema. As per the schema, bookById returns a Book object.
type Book {
id: ID!
title: String!
pageCount: Int
author: Author
bookStores: [BookStores]
}
Book type is defined as above. Keys in the map returned by the DataFetcherResult will be used to map the data to the fields defined in the schema, in this case, id, title and pageCount will get mapped to the data.
Note: You could define data fetchers for each of the fields such as title, pageCount and transform the response further but if you didn’t define any Graphql java will make use of PropertyDataFetcher which will resolve map or POJO data to the respective fields defined in the schema matching by the names.
Now our map has two more entries authorId and bookStores which contain ID to link to the data in the other maps.
We need to use these ID to resolve data so that a complete response will get returned to the customer.
Let’s add two more data fetchers to resolve data for fields author and bookStores.
author Data Fetcher
public DataFetcher getAuthorDataFetcher() {
return dataFetchingEnvironment - > {
final Map < String, String > book = dataFetchingEnvironment.getSource();
final String authorId = book.get("authorId");
return authors
.stream()
.filter(author - > author.get("id").equals(authorId))
.findFirst().orElse(null);
};
}
The way graphql works is that Book is a parent object and Author, BookStores are child objects. A tree path gets created and for each data fetcher call the parent data gets passed in to the child.
So, when author resolver gets called, the data of parent object Book gets passed in. In this case, it will be the map data which we returned from getBookByIdDataFetcher method.
We access the source data with call to dataFetchingEnvironment.getSource() and then get the authorId. We then filter the author data set to get the author details matching the author id and then return the map.
Returned map contains id, firstName and lastName entries which map to the Author type defined in the schema.
type Author {
id: ID
firstName: String
lastName: String
}
Now, we have resolved the author field in book type object. Likewise, we need to add data fetcher to resolve the bookStores field.
bookStores Data Fetcher
public DataFetcher getBookStores() {
return dataFetchingEnvironment - > {
final Map < String, String > book = dataFetchingEnvironment.getSource();
if (book.get("bookStores") != null) {
final List < String > bookStores = Arrays.asList(book.get("bookStores").split(","));
return stores
.stream()
.filter(store - > bookStores.contains(store.get("id")))
.collect(Collectors.toList());
} else {
return null;
}
};
}
As per our schema definition, we are to return a list of bookStores. So, in our data fetcher we return a list of bookStore objects.
For every object in the list it will look for an id field, find it by name in a map or via a getId() getter method and that will be sent back in the graphql response. It does that for every field in the query on that type.
Runtime Wiring
We had created our data fetchers previously where we had defined the logic to populate data for each of our fields.
We need wire this logic to the fields defined in the schema so that GraphQL java knows what data fetchers for each of the fields.
Remember the buildWiring method we had defined in our provider, we define our data fetchers in it as below.
@Autowired
private GraphQLDataFetchers graphQLDataFetchers;
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(TypeRuntimeWiring.newTypeWiring("Query").dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(TypeRuntimeWiring.newTypeWiring("Query").dataFetcher("listBooks", graphQLDataFetchers.listBooks()))
.type(TypeRuntimeWiring.newTypeWiring("Book").dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher()))
.type(TypeRuntimeWiring.newTypeWiring("Book").dataFetcher("bookStores", graphQLDataFetchers.getBookStores()))
.build();
}
Here, we have defined that when a query operation is invoked on bookById, getBookByIdDataFetcher() method needs to be called.
getBookByIdDataFetcher will return a map containing book details.
We didn’t define any data fetchers for the fields id, title and pageCount, so graphql java will use PropertyDataFetcher to resolve values for these fields.
We then created two data fetchers to resolve data for fields author and bookStores. We wire it up by defining a new type wiring for Book object and adding data fetcher for the fields author and bookStores as follows:
dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher())
dataFetcher("bookStores", graphQLDataFetchers.getBookStores())
So, GraphQL java will call data fetchers for each of the fields defined in the schema. It will know what data fetcher to call based on the runtime wiring definition. If in case, there is no data fetcher defined for a field it will make use of PropertyDataFetcher to resolve Map, List or POJO objects.
Serving over HTTP
Now our application is ready to serve HTTP requests.
Run the spring boot app which will make it available at http://localhost:8080/graphql
Curl
A standard GraphQL POST request should use the application/json content type.
It include a JSON-encoded body of the following form:
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue", ... }
}
where operationName and variables are optional fields.
curl -X POST \
http://localhost:8080/graphql \
-H 'Accept-Encoding: gzip, deflate' \
-H 'Content-Type: application/json' \
-d '{
"query": "query Books($id: ID!) { bookById(id: $id) { id title pageCount author { firstName lastName } } }",
"variables": { "id": "book-1" }
}'
Postman

In postman, you have to give the query and variables in separate windows.
Query:
query Books($id: ID!) {
bookById(id: $id) {
id
title
pageCount
author {
firstName
lastName
}
}
}
Variables:
{
"id": "book-1"
}
GraphQL Playground
GraphQL Playground is a handy tool with notable features:
-
Code completion based on schema introspection
-
Documentation based on schema introspection
SDL Directives
You can place directives on SDL elements and then write the backing logic once and have it apply in many places.
This idea of “writing it once” is the key concept here. There is only code place where logic needs to be written and it is then applied to all the places in the SDL that have a named directive.
For our book details application, we want introduce a restriction that certain fields can only be queried if the reason argument is supplied.
Declaring Directives
Let’s create a book view reason directive for this purposes and implement the logic for it.
bookViewReason.graphqls
directive @bookViewReason on FIELD_DEFINITION
Here we have mentioned that the directive location is at a field level.
Other valid directive locations are:
SCHEMA,
SCALAR,
OBJECT,
FIELD_DEFINITION,
ARGUMENT_DEFINITION,
INTERFACE,
UNION,
ENUM,
ENUM_VALUE,
INPUT_OBJECT,
INPUT_FIELD_DEFINITION
Let’s apply this directive to bookStores field by using @ annotation.
type Book {
id: ID!
title: String!
pageCount: Int
author: Author,
bookStores: [BookStores] @bookViewReason
}
What it means is that when the customer queries for the field bookStores the corresponding directive’s code logic will get invoked. We will be seeing next how we wire up the directive to the code logic.
Using Context
For whichever field this directive is invoked our intention is to check if the reason argument has a value available. This information won’t be directly available to us as the directive could be used in n-th tree position. So, we make use of localContext to pass on this information from the parent.
Let’s update our getBookByIdDataFetcher to pass this information via localContext:
GraphQLDataFetchers.java
public DataFetcher getBookByIdDataFetcher() {
return dataFetchingEnvironment - > {
final Map < String, String > localContext = new HashMap < > ();
localContext.put("reason", dataFetchingEnvironment.getArgument("reason"));
final String bookId = dataFetchingEnvironment.getArgument("id");
Map < String, String > bookDetails = books
.stream()
.filter(book - > book.get("id").equals(bookId))
.findFirst().orElse(null);
return DataFetcherResult.newResult()
.data(bookDetails)
.localContext(localContext)
.build();
};
}
Directive Logic
Now let’s define the backing logic for our directive.
BookViewReasonDirective.java
@Component
public class BookViewReasonDirective implements SchemaDirectiveWiring {
@Override
public GraphQLFieldDefinition onField(SchemaDirectiveWiringEnvironment<GraphQLFieldDefinition> environment) {
final GraphQLFieldsContainer fieldsContainer = environment.getFieldsContainer();
final DataFetcher originalDataFetcher = environment.getCodeRegistry().getDataFetcher(fieldsContainer, environment.getFieldDefinition());
final DataFetcher dataFetcher = DataFetcherFactories.wrapDataFetcher(originalDataFetcher, ((dataFetchingEnvironment, value) -> {
final String reason = ((Map<String, String>) dataFetchingEnvironment.getLocalContext()).get("reason");
if(StringUtils.isEmpty(reason)) {
final Map<String, Object> extensions = new HashMap<>();
extensions.put("errorCode", "001");
extensions.put("errorMessage", "Reason required for viewing book store details");
final GraphQLError graphQLError = GraphqlErrorBuilder.newError()
.message("Reason required for viewing book store details")
.extensions(extensions)
.path(dataFetchingEnvironment.getExecutionStepInfo().getPath())
.build();
return DataFetcherResult.newResult().error(graphQLError).build();
}
return value;
}));
final FieldCoordinates coordinates = FieldCoordinates.coordinates(fieldsContainer, environment.getFieldDefinition());
environment.getCodeRegistry().dataFetcher(coordinates, dataFetcher);
return environment.getElement();
}
}
Here, we use DataFetcherFactories helper function wrapDataFetcher to wrap an existing data fetcher and map the value once it completes.
Inside the function we get the value for reason argument from the local context and validate if it’s present.
If it’s not present we return GraphQLError as result otherwise the original value.
We then update the wrapped data fetcher in the code registry so that it will get invoked in place of the original data fetcher.
Wiring Directives
Now let’s wire up the directive and code logic in our buildWiring function.
GraphQLProvider.java
@Component
public class GraphQLProvider {
@Autowired
private BookViewReasonDirective bookViewReasonDirective;
...
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(TypeRuntimeWiring.newTypeWiring("Query").dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(TypeRuntimeWiring.newTypeWiring("Query").dataFetcher("listBooks", graphQLDataFetchers.listBooks()))
.type(TypeRuntimeWiring.newTypeWiring("Book").dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher()))
.type(TypeRuntimeWiring.newTypeWiring("Book").dataFetcher("bookStores", graphQLDataFetchers.getBookStores()))
.directive("bookViewReason", bookViewReasonDirective)
.build();
}
}
Wherever we want this code logic to get applied we just add the SDL directive to the respective fields.
Tools
https://github.com/graphql/graphiql - In-browser IDE for exploring GraphQL
https://graphqleditor.com/ - Visual Editor & GraphQL IDE
https://apis.guru/graphql-voyager/ - Represent any GraphQL API as an interactive graph
https://github.com/imolorhe/altair - A beautiful feature-rich GraphQL Client for all platforms